Organic rankings are increasingly influenced by clarity of intent. When search engines encounter competing URLs for the same query, the result is often reduced visibility for all of them. In an environment where AI-powered mentions are replacing traditional search results, such conflicts can erase your presence from high-value placements entirely.
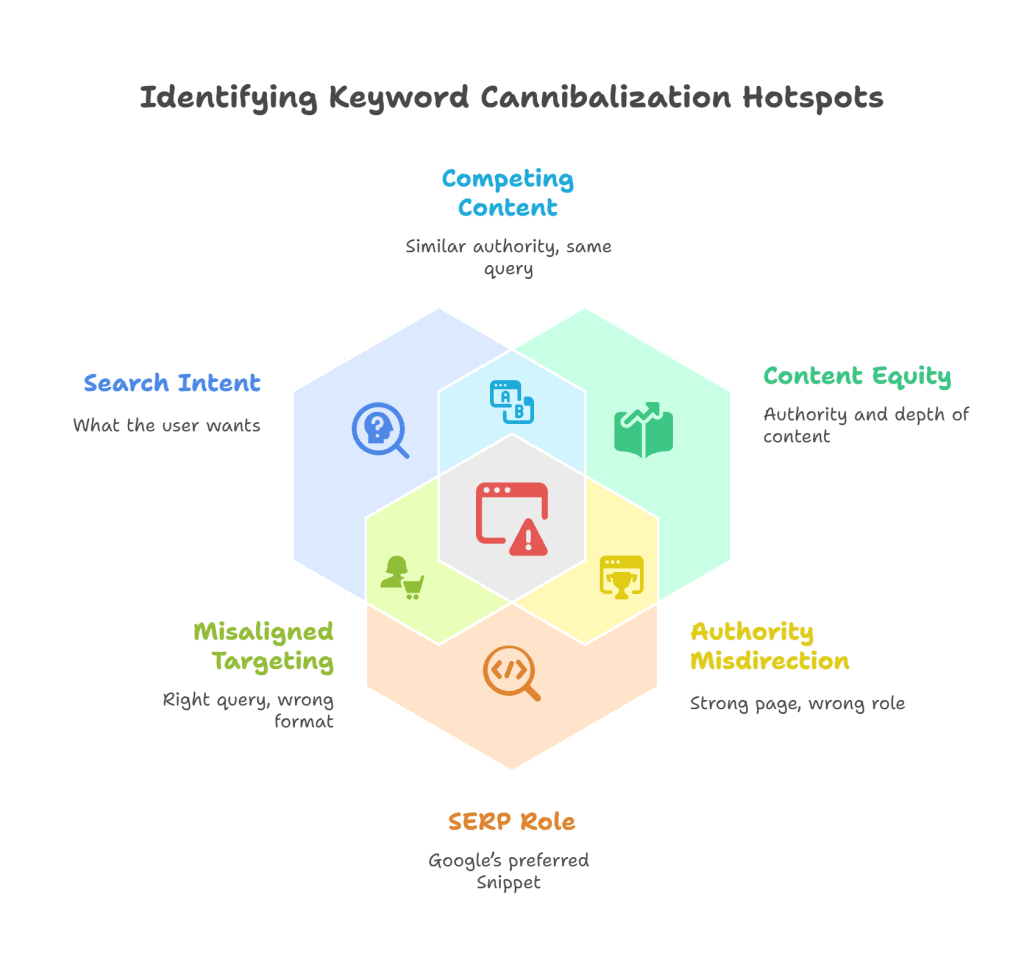
Keyword cannibalization occurs when more than one page targets the same keyword and satisfies the same search intent. This creates competing signals that divide link equity, weaken topical authority, and waste crawl budgets.
According to SEMrush, 63 percent of websites have cannibalization issues. BrightEdge reports that Google’s AI Overviews now appear in 11 percent of queries, a figure that has increased by 22 percent year-over-year. Pages with conflicting intent signals are far less likely to appear in these results.
Resolving the issue involves accurate detection, objective prioritization of fixes, targeted technical and content adjustments, and implementing measures to prevent the problem from returning.
Understanding keyword cannibalization
In search, there is rarely room for two winners. When multiple pages signal equal relevance for the same query, algorithms are forced into a choice. Sometimes the decision swings between URLs, other times neither page secures the position, leaving the opening for a competitor.
Keyword cannibalization describes this direct competition at the query level. It differs from content cannibalization, where overlap exists in topic but not necessarily in targeted search terms. The former is easier to measure, often revealing itself through fluctuating rankings and inconsistent click distribution.
Google’s selection process extends beyond keyword usage. Internal link pathways, anchor text patterns, backlink distribution, and historical engagement all shape which URL earns priority. Google’s own guidance on consolidating duplicate URLs confirms that these signals can merge into one dominant page or fragment across several, depending on site structure.
Research by Ahrefs shows that cannibalized keywords often trigger fluctuations in ranking URLs over time, a visible sign of split authority and unstable intent targeting.
Not all overlap is detrimental. Mixed-intent keywords, such as those serving both informational and transactional purposes, can support multiple rankings if each page clearly fulfills a different need. The same applies to branded searches where showing both a homepage and a high-authority subpage reinforces presence across the results.
The challenge and the opportunity lies in recognizing where overlap builds SERP dominance and where it silently erodes authority. The next section examines how the latter impacts performance in measurable, often underestimated ways.
Why keyword cannibalization damages search performance
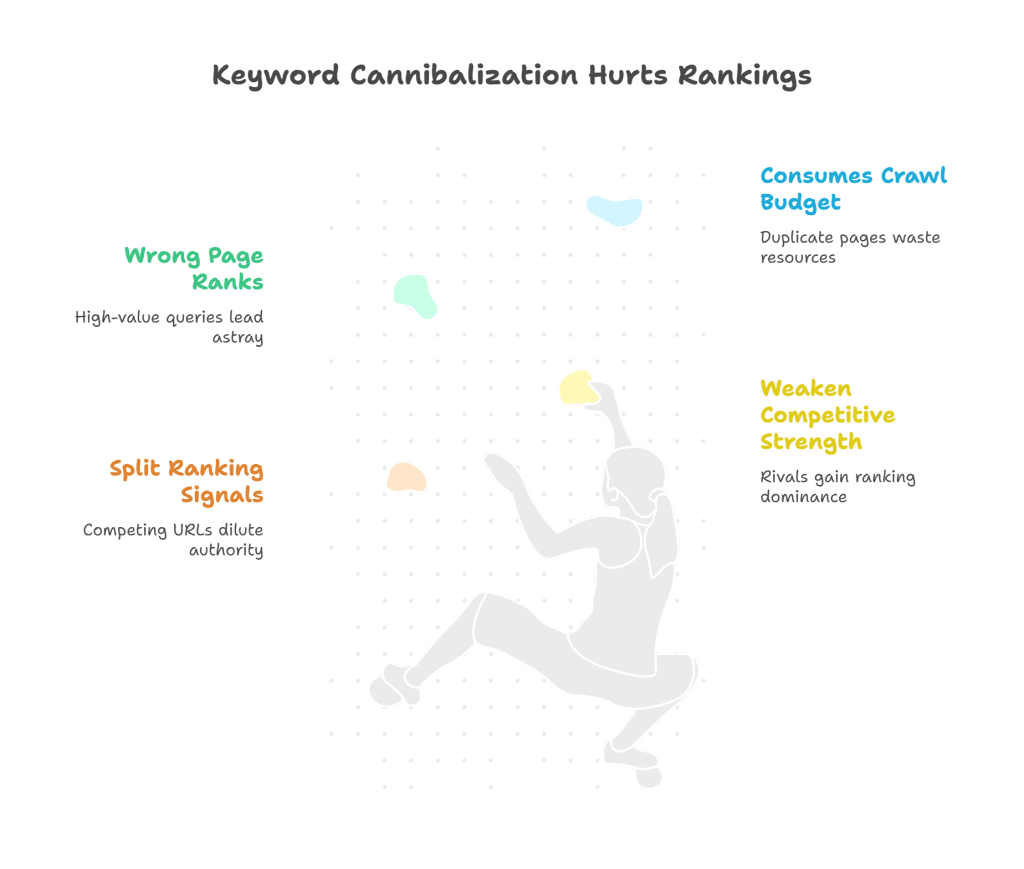
Search engines evaluate individual URLs, not domains, when determining which page to rank. When two pages from the same site both appear viable for a query, ranking signals, backlinks, authority, engagement are split. This weakens each page’s competitive strength, creating an opening for rival domains to take the lead.
The effect is measurable. In a documented case study by Backlinko, consolidating two competing URLs into one through a merge-and-redirect resulted in a 466 percent increase in clicks. The improvement was not solely from higher rankings. With a single, intent-matched page, searchers consistently saw the most relevant result, driving greater click-through even when position remained constant.
Misalignment of search intent compounds the loss. If an informational page outranks a transactional one for a high-value keyword, visibility remains but conversion potential declines. This mismatch can silently erode revenue while surface metrics like impressions or rank appear stable.
Crawl budget is also consumed inefficiently. Search engines allocate finite resources to re-crawling and re-evaluating URLs. When multiple pages compete for the same terms, bots revisit and index them repeatedly, diverting resources from fresher or strategically important content. Over time, this delays the discovery of new pages and limits the site’s ability to capitalize on emerging queries.
The consequences extend beyond rankings. According to SE Ranking, 18 percent of cannibalized keywords lose visibility for both competing pages within six months, suggesting that Google may suppress multiple URLs from the same domain in favour of a single external result.
Left unresolved, cannibalization progressively compounds. Each conflicting URL dilutes the clarity of a site’s topical authority, undermining rankings, conversions, and eligibility for high-impact SERP features.
How to check for keyword cannibalization
Keyword cannibalization can be checked by identifying when multiple URLs from the same domain rank for the same query. This is confirmed by using Google Search Console, SERP checks, crawl data, and log analysis.
1. Index check using Google Search Console
Start by filtering a target keyword in Google Search Console. Navigate to the Performance tab to view all URLs ranking for that query. Multiple results from the same domain indicate keyword overlap.
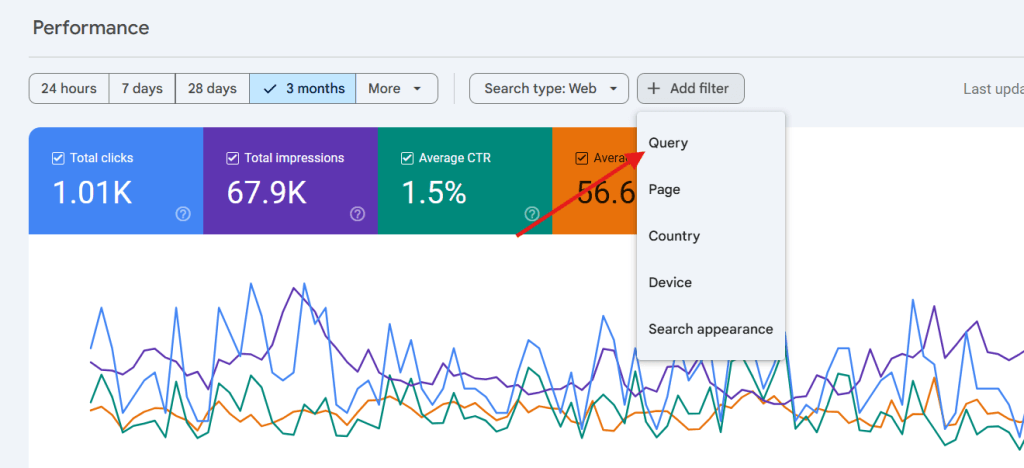
Example: Filtering for best CRM software shows both /best-crm-software/ and /crm-comparison/ appearing under the same query. This signals immediate conflict.
2. Live index inspection with site search
Use a site:yourdomain.com “exact keyword” query in Google Search to verify how many indexed pages target the same phrase. This confirms if the overlap is visible to the search engine.
Example: site:example.com “best CRM software” returns both a blog guide and a tools list page with similar phrasing in snippets.
3. SERP host clustering across device types
Run the same query on mobile and desktop in private mode. If different URLs from your domain appear based on device, or swap positions frequently, search engines have not resolved the ranking preference.
Example: email automation software shows /email-automation-guide/ at #5 on desktop and /best-email-tools/ at #4 on mobile.
4. Historical URL position tracking
Export keyword rankings over several weeks using GSC or a SERP tracker. Check for URL swapping on the same query. If two pages alternate positions, neither has secured dominance for the term.
Example: project management tools toggles weekly between /pm-guide/ and /tools-for-project-management/.
5. Title and H1 duplication audit
Crawl the site using Screaming Frog or Sitebulb and export the Title and H1 reports. Pages sharing identical or similar elements often compete, even if their primary keywords vary.
Example:
/seo-tips/ and /seo-tips-2025/ both use “10 SEO Tips for Beginners” as the title and heading, creating a conflict for intent clarity.
6. Content intent mapping and classification
Assign a single intent to each keyword (informational, transactional, navigational, or mixed). Map that intent to one preferred URL. Pages with overlapping or ambiguous intent contribute to cannibalization even if targeting different terms.
Example: cloud migration strategy and how to migrate to the cloud appear distinct but both satisfy informational intent. Without separation, they risk competing for the same visibility.
7. Internal anchor clustering
Export all internal links and filter by anchor text. If the same anchor points to more than one URL, internal signals are fragmented.
Example: “email automation tools” links to both /automation-software/ and /email-tools-overview/.
8. Log file pattern analysis
Analyse raw server logs to compare Googlebot crawl frequency for competing URLs. When two pages are crawled equally for a keyword cluster, it suggests the search engine has not resolved the preferred candidate.
Example: Googlebot hits /crm-tools-guide/ and /crm-software/ nearly equally across several weeks.
10. SERP snippet variation check
Compare how Google displays snippets for overlapping pages across queries. If snippet formats switch between bullet points and paragraph summaries, Google is testing relevance between the URLs.
Example: technical SEO checklist shows a bullet-style snippet for /seo-checklist/ one week and a paragraph-style for /seo-guide/ the next.
11. Impression share ratio in GSC
In GSC, export query data for both pages and compare impression percentages under the same keyword. A near 50/50 split confirms neither URL holds query authority.
Example: For social media scheduler, /top-schedulers/ has 52% impressions and /scheduling-guide/ has 48%.
12. Named entity overlap using NLP
Use entity extraction tools (e.g., Google NLP API or spaCy) on both URLs. Pages sharing high-weight entities may compete, even if their primary keywords differ.
Example: Both /crm-software-guide/ and /sales-platform-overview/ mention “HubSpot,” “Salesforce,” and “Zoho,” triggering topic-level overlap.
13. Rendered content duplication
View Rendered Source to check for dynamic sections (FAQs, tables) that load via JavaScript. If identical modules appear across multiple pages, this may cause cannibalization post-rendering.
Example: A table listing “Top 5 CRM tools” loads identically on /crm-software/ and /sales-crm-guide/.
| Detection Method | Data Source | Quick Check |
| Index check | GSC | Filter by query, list all ranking URLs |
| Live site search | Google SERP | site:domain.com “keyword” |
| Device clustering | Google SERP | Compare desktop vs mobile |
| Historical swap | GSC / Rank Tracker | Track alternating URLs over time |
| Title/H1 audit | Screaming Frog | Export and compare |
| Intent mapping | Content Brief | Assign 1 URL per intent |
| Internal anchor check | Screaming Frog | Filter anchor text pointing to multiple URLs |
| Log pattern | Server logs | Compare bot crawl frequency |
| Snippet variation | Google SERP | Look for changing formats |
| Impression share | GSC | Compare % split between URLs |
By combining these detection workflows, you move beyond surface-level checks into systemic pattern recognition. Accurate detection reveals where authority is fragmented, enabling corrective actions such as consolidating duplicate signals, redirecting low-performing variants, or refining on-page differentiation to restore topical clarity.
How to prioritize which keyword cannibalization issues to fix
Not all cannibalization demands action. Fixing everything introduces risk, especially if pages have earned links, rankings, or conversions independently. The key is to triage conflicts based on impact, traffic value, conversion role, and intent accuracy. Take action only when cannibalization suppresses your highest-performing asset.
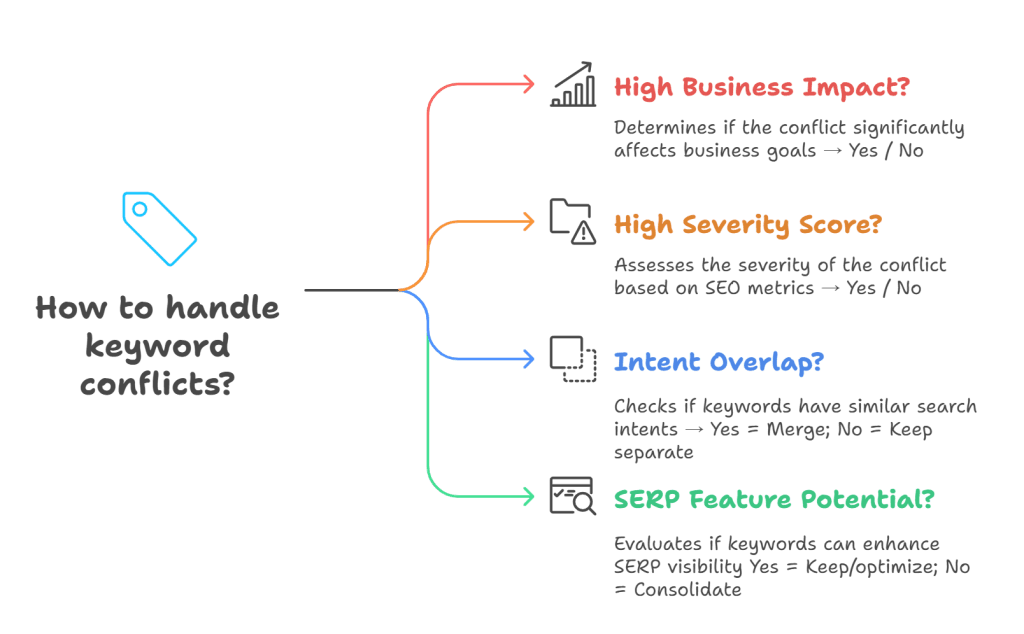
Classify by business impact
Prioritize conflicts based on their role in your marketing and conversion ecosystem. Assign each cannibalized keyword a weighted value using three axes:
- Search potential: volume and likelihood of CTR
- Conversion role: whether the query sits near commercial or transactional paths
- Brand alignment: degree to which the term anchors your authority or positioning
Example: A conflict between /project-management-tools/ and /pm-comparison/ targeting a mid-funnel keyword matters more than one involving /what-is-project-management/, even if the latter has higher search volume.
Score cannibalization severity
To estimate SEO damage, assign a cannibalization health score for each affected query:
Health Score = Impression Share Variance × Intent Mismatch × URL Volatility
- Impression Share Variance: From GSC, based on the difference in impressions across URLs
- Intent Mismatch: Scored as Low (similar intent), Medium (partial), High (conflicting)
- URL Volatility: How often the ranking URL changes week-over-week
Scoring scale:
- Impression Share Variance: 1 = low split, 3 = ~50/50 split
- Intent Mismatch: 1 = low, 3 = high
- URL Volatility: 1 = stable, 3 = weekly swapping
Example: Keyword = “best CRM software”
- Impression Share Variance = 3
- Intent Mismatch = 2
- URL Volatility = 3
Health Score = 3 × 2 × 3 = 18 (High Priority)
A higher score signals weaker query-to-content alignment and should be prioritized for remediation.
Apply a decision matrix
Once each conflict is scored, apply this logic-based framework:
| Conflict Type | Business Impact | Severity Score | Recommended Fix |
| Same intent, one URL underperforms | High | ≥ 7 | Merge + redirect weaker URL |
| Same intent, both underperform | High | ≥ 7 | Consolidate into unified page |
| Different intents, both valuable | Medium | 4–6 | Keep both, separate intent signals |
| Intent mismatch | Medium | 4–6 | Retarget mismatched page |
| Neither ranks | Low | ≤ 3 | Rebuild best-fit URL |
These fixes should reinforce canonical focus, tighten crawl signals, and recover diluted equity.
For complex conflicts where both pages generate traffic or links, deeper signal audits can help you make data-backed decisions without undermining SEO value.
Link equity distribution audit
Compare backlink quantity and anchor diversity between conflicting URLs. Preserve or merge into the page with stronger external signals and better semantic fit.
Example: Ahrefs shows /crm-platforms/ has fewer links than /crm-software/, but higher authority domains link to it with anchor text matching the query. Redirecting to /crm-platforms/ would lose topical alignment and contextual strength.
Click-through rate divergence
Compare GSC CTR across the two URLs. If one has a significantly lower CTR despite better rank, it’s mismatched to intent and a candidate for re-optimization or de-prioritization.
Example: /email-marketing-guide/ ranks #3 but has a 0.8% CTR. /best-email-tools/ at #5 gets 2.4%. Signals that Google is showing the wrong page.
SERP feature eligibility scoring
Evaluate both pages for their potential to trigger rich results like featured snippets, PAA, or AI answers. Prioritize the one structurally optimized for these placements.
Example: /seo-checklist/ has structured data, scannable headings, and FAQ schema. /seo-guide/ is dense and lacks markup. The checklist page is a better canonical target.
Semantic coverage delta
Run both URLs through tools like MarketMuse or Surfer to see which covers more entities, subtopics, and context-relevant queries. Favor the one with superior semantic depth.
Example: /cloud-migration-strategy/ covers 18 related entities and synonyms. /cloud-migration-process/ covers 9. Choose the more comprehensive URL to consolidate value.
Log-weighted recrawl priority
Use server logs to determine which URL Googlebot visits more frequently. If both URLs perform similarly, prioritize keeping the one with higher recrawl weight — it signals stronger trust.
Example: In the last 30 days, Googlebot hit /saas-security/ 24 times vs. /cloud-security-guide/ 8 times. Unless there’s a conversion reason to keep the latter, it should be redirected.
These advanced filters prevent overcorrection and help avoid unnecessary redirects or loss of earned equity. Once conflicts are triaged and prioritized, the next step is applying the right fix, consolidation, re-optimization, or structural separation.
How to fix keyword cannibalization with precision, not guesswork
Fixing keyword cannibalization isn’t about deleting pages or funneling everything into a single URL. Effective resolution starts with understanding each page’s intent, authority signals, and role in the SERP. Only then can you apply the appropriate fix whether it’s merging, reoptimizing, canonicalizing, or structurally isolating the asset with confidence and minimal ranking disruption.
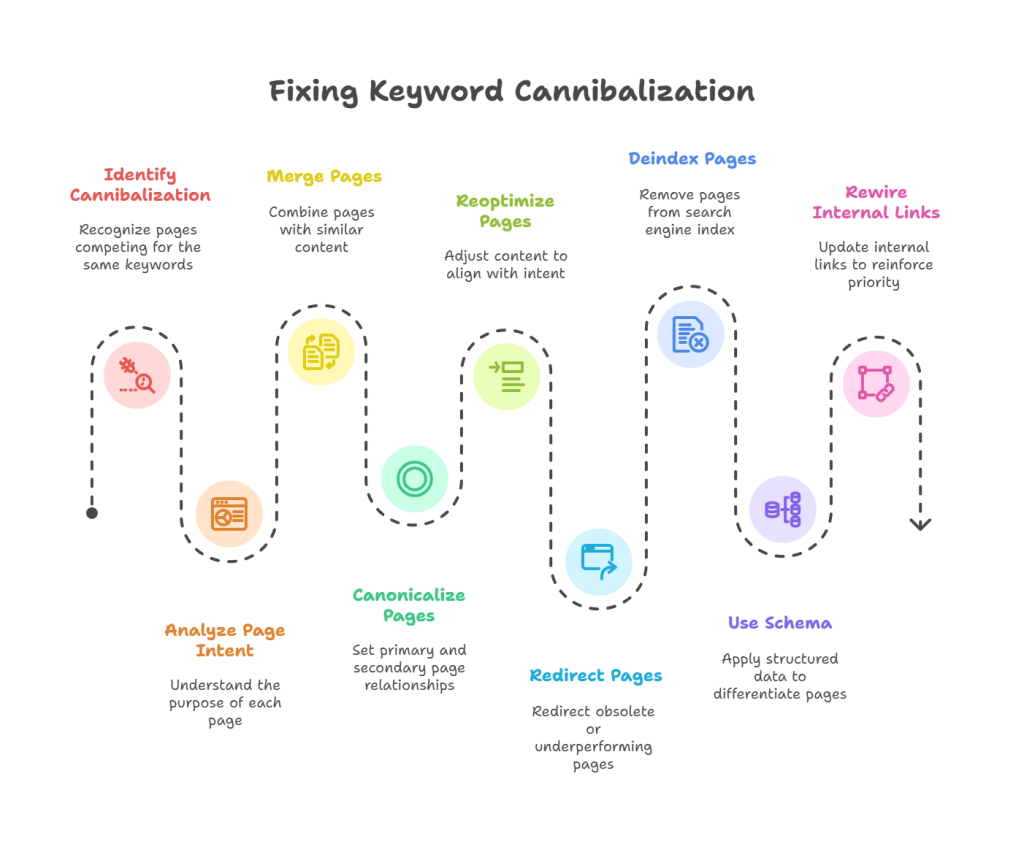
Merge when semantic overlap is near-total, and link signals are fragmented
If two or more URLs compete for the same query with similar intent and shallow differentiation, merging is the cleanest fix. Use your scoring sheet to confirm:
- Matching intent clusters (navigational vs informational vs commercial)
- Similar content structure and depth
- Link equity split across pages
Technical action:
- Choose the highest-performing URL based on backlink profile, crawl budget, and CTR.
- Consolidate all content into that page, enriching it with missing sections from the others.
- Apply 301 redirects from the deprecated URLs to the canonical one.
- Re-request indexing for the new canonical to accelerate re-evaluation.
Canonicalize when you control duplication and want to preserve utility
Sometimes, two assets need to exist like a product page and a filtered collection page, but you don’t want both indexed. If internal value exists (e.g., UX, filters, navigation), canonicalization avoids full deindexing.
Technical action:
- Set a <link rel=”canonical”> tag from the secondary page to the primary one.
- Ensure internal links point to the canonical URL to reinforce signal consolidation.
- Block parameters or filtered variants from being indexed via robots.txt or noindex where needed.
3. Reoptimize when intent or query targeting is misaligned
Pages that overlap due to shared queries but have different true intents should be refocused, not merged. This fix applies when:
- One page ranks intermittently or for the wrong variant
- Title and H1 tags show overlap, but body content differs
- SERP features suggest divergent query behavior (e.g., People Also Ask vs product carousel)
Technical action:
- Update title, meta, and H1 to tightly match the correct intent
- Remove or rewrite overlapping sections
- Add semantic keywords that reinforce divergence (e.g., “pricing,” “review,” “how to,” “comparison”)
- Adjust internal anchor texts to reflect new targeting
Redirect only when the cannibal is obsolete or underperforming
Redirects are irreversible at scale. Apply only when:
- The cannibal page has no unique value or search demand
- It receives low traffic, low engagement, or thin backlinks
- Log data shows minimal bot interest or crawl frequency
Technical action:
- Use 301 (not 302) redirects
- Log all redirect rules and annotate analytics platforms to avoid attribution loss
- Monitor crawl logs to verify de-duplication and budget consolidation
Deindex when the page must exist for users, but not for search engines
If an asset serves UX goals (e.g., printable version, login page, internal search results) but causes cannibalization, exclude it from the index entirely.
Technical action:
- Apply a <meta name=”robots” content=”noindex, follow”> directive
- Remove XML sitemap entries for that page
- Maintain internal linking only where essential to user flows
Use schema and SERP role modifiers to reposition page purpose
Even when two pages appear similar, you can differentiate them in Google’s eyes by altering their feature eligibility. This is especially useful when both must exist but should rank for different layers of the same query stack.
Technical action:
- Add FAQ or HowTo schema to one page
- Add Product or Review schema to the other
- Reformat layout and structure to match featured snippet triggers (e.g., step lists, tables)
- Check SERP landscape using real-time tools to map feature eligibility per URL
Internal link rewiring to reinforce priority signals
When cannibalization is mild, often the cause is unintended link dilution from navigation, breadcrumbs, or blog interlinking. Fixing the internal structure often resolves ambiguity without rewriting content.
Technical action:
- Run a crawl to extract all internal anchor texts pointing to both URLs
- Replace diluted anchors pointing to the weaker page
- Use consistent, intent-reinforcing anchors for the primary URL
- Update nav menus or category links if legacy pages are overlinked
A/B test content variants before merging
If pages differ in format or audience segmentation, validate performance before merging.
- Use server-side A/B tools to test engagement (CTR, scroll, dwell).
- Only consolidate once the stronger UX pattern is statistically proven.
Reinforce recrawl using sitemap priority cues
After any major change, make it crawlable-fast.
- Modify sitemap <priority> and <lastmod> fields to flag freshness.
- Ping sitemap URL for re-evaluation.
Audit Googlebot behavior post-fix via server logs
Verify indexation and crawl behavior align with your fix.
- Compare crawl frequency and depth before vs after fix.
- Confirm suppression of deprecated URLs and focus on canonical targets.
Add entity-level schema to disambiguate topic overlap
When two pages rank for the same topic without clear entity separation:
- Use structured data with unique @type definitions.
- Link to authoritative entity references (e.g., Wikidata, product spec pages).
Use hreflang to resolve global cannibalization
For multinational sites with multiple localized variants:
- Implement proper hreflang mappings.
- Ensure canonicalization respects regional targeting.
How to track recovery and validate fixes post-cannibalization
Applying the fix is only half the equation. The other half is proving it worked, and detecting if further action is needed. Precision-led remediation must be followed by quantifiable recovery signals, drawn from crawl behavior, indexation patterns, SERP volatility, and traffic shifts.
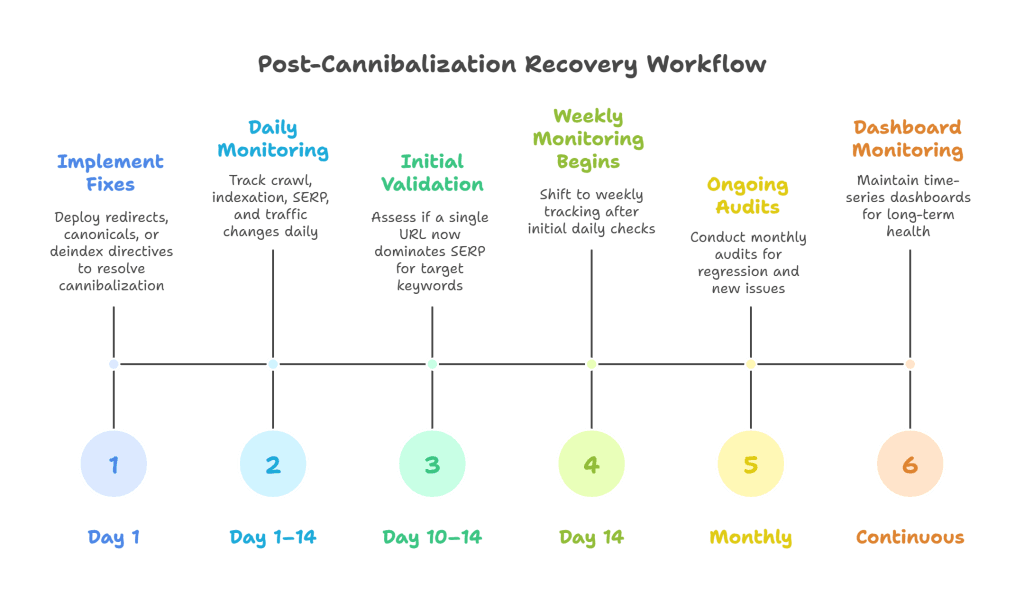
Below is a step-by-step post-fix monitoring workflow built for accuracy, not assumptions.
Confirm crawl acceptance with log-level validation
After implementing redirects, canonical tags, or deindex directives, verify that Googlebot’s behavior adapts accordingly.
What to check:
- Has Googlebot stopped crawling deprecated URLs?
- Are redirected or canonical target URLs seeing increased crawl frequency?
- Is crawl depth shifting toward your revised internal architecture?
How to check:
- Use server access logs parsed via Screaming Frog Log Analyzer, JetOctopus, or a self-hosted ELK stack.
- Compare pre- and post-fix crawl patterns by user-agent, timestamp, and response code.
Monitor indexation state and SERP positioning
Fixes involving canonicalization, merging, or noindex take time to reflect in Google’s index. Track indexation lag and SERP recalibration using both GSC and third-party tools.
What to track:
- Index coverage status changes in GSC (e.g., “Duplicate, submitted URL not selected as canonical” resolving to “Indexed”)
- Fluctuations in SERP positions using daily rank trackers (e.g., SE Ranking, AccuRanker)
- Visibility shifts in featured snippet, PAA, and SERP feature eligibility
Recommended interval: Monitor daily for the first 10–14 days, then shift to weekly tracking.
Track keyword realignment and rank consolidation
The goal of deconfliction is not just “no cannibalization”, it’s rank stability with consolidated authority. You should see a single URL dominating the SERP cluster, rather than multiple URLs oscillating or suppressing each other.
How to validate:
- Extract keyword-level ranking history for all affected URLs.
- Verify if a single URL now consistently ranks across cannibalized queries.
- Use tools like Ahrefs or Semrush to check “Traffic Share by URL” for a given keyword cluster.
Warning signal: If rankings remain volatile across multiple URLs, your fix may have lacked intent clarity or content differentiation.
4. Compare traffic deltas and CTR uplift
Once the conflict is resolved, the dominant URL should absorb traffic previously split between cannibals and improve its CTR due to stronger alignment.
How to validate:
- Use GSC performance reports filtered by URL to compare clicks and impressions pre- and post-fix.
- Segment by query group or page grouping.
- Track net CTR change for high-intent commercial queries.
Target outcome: Higher CTR on fewer URLs with stronger impression-to-click conversion.
Watch for soft regression via fresh indexation or internal link drift
Even after successful remediation, new content or CMS changes can reintroduce keyword overlap. You need guardrails.
How to prevent relapse:
- Set up alerting for duplicate query coverage using automated SEO QA tools or custom GSC scripts
- Lock in canonical structure with CMS rules
- Run monthly audits for:
- Reintroduced thin variants
- Tag/category page indexation
- Navigation changes affecting anchor consistency
Use time-series dashboards for continuous recovery visibility
Instead of checking ad hoc, build dedicated dashboards that track keyword cannibalization health over time.
What to include:
- Rank volatility across affected query groups
- Number of URLs per keyword in top 20 positions
- CTR trends segmented by target vs deprecated pages
- Crawl status for canonical and redirected URLs
Tools to build with:
- Looker Studio with GSC and BigQuery
- Ahrefs API + Semrush API + Google Sheets
Reinforce with reindex requests and link recalibration
For critical pages, nudge Google’s evaluation window:
- Use URL Inspection API or manual “Request Indexing” in GSC for updated canonicals or merged pages.
- Rebuild high-impact internal links toward consolidated pages.
- Update backlinks via outreach if key referring domains still point to deprecated URLs.
When done correctly, you should observe:
- Reduction of conflicting URLs for target queries
- Stable ranking of a single canonical URL per keyword group
- CTR uplift on primary URLs
- Decreased crawl activity on deprecated or excluded assets
- Clean indexation with minimal duplication flags
How to future-proof your site against keyword cannibalization
Once you’ve cleaned up keyword cannibalization, the next challenge is keeping it from returning. As your content inventory grows and team members rotate, risk creeps back in usually through fragmented topical targeting, uncoordinated publishing, and inconsistent internal signals.
This section outlines a set of prevention systems designed to stop cannibalization before it begins through editorial workflows, technical governance, and scalable intent mapping.
Codify query-to-URL ownership before publishing
Every new target keyword must map to a single intended URL from the first draft, not retroactively.
How to implement:
- Maintain a keyword-to-URL index in a shared sheet or content database.
- Require writers to check this index before pitching or drafting.
- If overlap exists, define whether the new content will:
- Extend the existing URL
- Replace it
- Or serve a different intent (e.g., comparison vs guide)
Tip: Use a master spreadsheet or Airtable to tag each keyword with target intent, funnel stage, and SERP role.
Cluster semantically before structuring content
Most cannibalization occurs when content clusters are treated like silos, not interconnected topic ecosystems.
Prevention tactics:
- Use tools like Surfer, Clearscope, or MarketMuse to identify topic boundaries before assigning content.
- Map content to primary entities, not just keywords.
- Ensure only one core piece targets the primary query other pieces should support it via internal links, not compete.
Engineer intent separation at the page level
When multiple pages cover related queries (e.g., “CRM software” vs “best CRM tools for startups”), they must have clear intent divergence in structure and markup.
Structural safeguards:
- Use distinct H1s, meta titles, and schema types per page.
- Avoid reusing section blocks or content modules across URLs in the same cluster.
- Apply SERP-aware formatting: comparison tables, pros/cons, tutorials, pricing breakdowns — based on query pattern.
Govern internal links with directional rules
Unstructured internal linking is one of the top causes of accidental cannibalization.
Governance model:
- Define a primary target URL per keyword group, and route most internal links there.
- Avoid rotating anchors across multiple URLs with similar topics.
- Audit navigation templates and automated widgets to prevent duplication of internal link equity.
Implementation tip: Crawl your site monthly with Screaming Frog or Lumar to export anchor text-to-target maps and detect dilution.
Standardize schema markup to clarify page purpose
Schema isn’t just for rich results. It trains search engines to understand what each page is meant to do.
Preventive actions:
- Define a schema type for each content category in your CMS or content brief (e.g., Article, Product, HowTo, FAQPage).
- Use custom JSON-LD templates per intent layer.
- Align schema types with SERP features expected for each query (e.g., HowTo for “setup” queries, Product for transactional).
Introduce SEO QA into the content release cycle
No page should go live without a cannibalization safety check.
What to include in the QA checklist:
- Does this keyword already exist in the site’s rank index?
- Does the new page overlap in intent with an existing page?
- Is the internal link priority clear and correct?
- Are canonical and schema tags correctly set?
Optional: Integrate this QA into your CMS publishing workflow using Airtable, Asana, or Git-based workflows with SEO reviewers.
Run scheduled health checks for early detection
Even with strong processes, regressions happen. Schedule audits to catch them before they affect rankings.
Recommended cadence:
- Monthly: Crawl for duplicate or near-duplicate URLs by content and metadata
- Biweekly: GSC query overlap audit (same query, multiple pages)
- Quarterly: URL-to-keyword ownership reconciliation and internal link scoring
Automate with:
- Screaming Frog + Excel macros
- Google Search Console API
- Looker Studio dashboards connected to BigQuery or Ahrefs API or Semrush API
With these systems in place, you’re not just reacting to cannibalization you’re architecting your content to avoid it entirely. Future growth becomes additive, not competitive. Every new page reinforces your topical footprint without triggering internal conflict.
Run a zero-fluff keyword cannibalization audit in 60 minutes
Fixing keyword cannibalization doesn’t require a full SEO platform or months of analysis. With a structured, signal-led approach, you can identify conflicts, score severity, and take action — all within an hour.
Use the following step-by-step audit framework to run a complete diagnostic, prioritize issues, and apply the right fix with confidence.
Step 1: Extract your target keyword set (5 minutes)
Pull all commercial- or informational-intent keywords you’re actively targeting.
Tools:
- Ahrefs / Semrush → Export keyword data per site section or content cluster
- GSC → Performance report → Filter by query + URL + CTR
Output:
- Keyword list with associated URLs, CTR, impressions, and rank
Step 2: Identify multiple URLs per query (10 minutes)
Detect where more than one page is ranking or receiving impressions for the same keyword.
Method:
- In GSC, group queries and filter for 2+ URLs per query
- In Ahrefs/Semrush, look for “multiple URLs in top 20” for a keyword
Output:
- Conflict list with overlapping URLs per query
Step 3: Score each conflict by severity (15 minutes)
Use your audit scoring sheet to evaluate which conflicts matter and which are false positives.
Scoring criteria:
- Link equity dilution
- CTR divergence
- SERP volatility
- Intent ambiguity
- Crawl behavior (if log data available)
Tools:
- Internal link audit (Screaming Frog)
- CTR comparison (GSC)
- Crawl logs (optional)
Output:
- Prioritized conflict list with recommended fix type (merge, reoptimize, etc.)
Step 4: Choose the fix using the decision tree (10 minutes)
Apply the remediation logic based on the page’s role, signals, and audit outcome.
Reference:
- Fix decision tree
- Scoring logic → Fix recommendation mapping
Fix types include:
- Merge
- Canonicalize
- Redirect
- Reoptimize
- Deindex
- Internal link isolation
- Schema divergence
Output:
- Fix plan per conflict (with rationale)
Step 5: Apply technical changes (10 minutes)
Implement or schedule the fix — manual or via CMS/backend.
Actions include:
- Set canonical tags
- Deploy redirects
- Edit meta + headings
- Adjust schema
- Update nav/internal links
- Submit sitemap or reindex via GSC
Output:
- Confirmed fix deployments with annotated change log
Step 6: Monitor recovery and suppression (10 minutes)
Post-fix, validate that Google is recognizing and responding to your changes.
Quick checks:
- GSC → Inspect canonical status
- Check if only one URL ranks now
- Watch CTR and traffic consolidation
- Crawl logs (if applicable) to verify suppression of deprecated URLs
Output:
- Confirmation of resolved cannibalization and improved targeting
This audit framework gives you:
- A clear detection method
- A signal-weighted prioritization model
- A fix logic tree
- A validation loop
- And a way to repeat the process monthly
You’ve now built a closed-loop SEO ops system for managing keyword cannibalization, not a one-time cleanup. You’ve operationalized a problem that most teams ignore until rankings drop.
There’s no guesswork. No bloated tooling. Just a tactical framework you can run on any site, at any scale.